Build your own AI: how to teach GPT to search the web and execute code
Large Language Models such as GPT-3, ChatGPT, Bing AI, and Google Bard have recently demonstrated stunning advances in conversational capabilities, text summary, translation, code creation and many other applications. Microsoft's new AI-powered search assistant Bing showed how these capabilities can be further enhanced by allowing the AI agent to access conventional search engines and read web pages. In this post, we will take a closer look at the Python package langchain, which allows us to easily combine an LLM such as GPT-3 with other functionalities like web search, a Python interpreter, and a terminal session for code execution. With just 50 lines of code, you can create your own personalized AI agent that retrieves information from the internet, implements algorithms in Python, and runs code to solve tasks.
Note: The AI model that is described in this blog post is able to execute arbitrary Python code and system commands! Please execute the code snippets from this blog post in a sandbox environment such as Replit.com, to avoid loss of data or other damage due to the execution of potentially harmful commands.
Take a look at console output displayed below. It shows the answer of a custom AI to the question "What is the 11th prime number?" The AI is based on GPT-3 (text-davinci-003) by OpenAI, and it is combined with the capabilities to search Google, execute Python code, and to execute terminal commands.
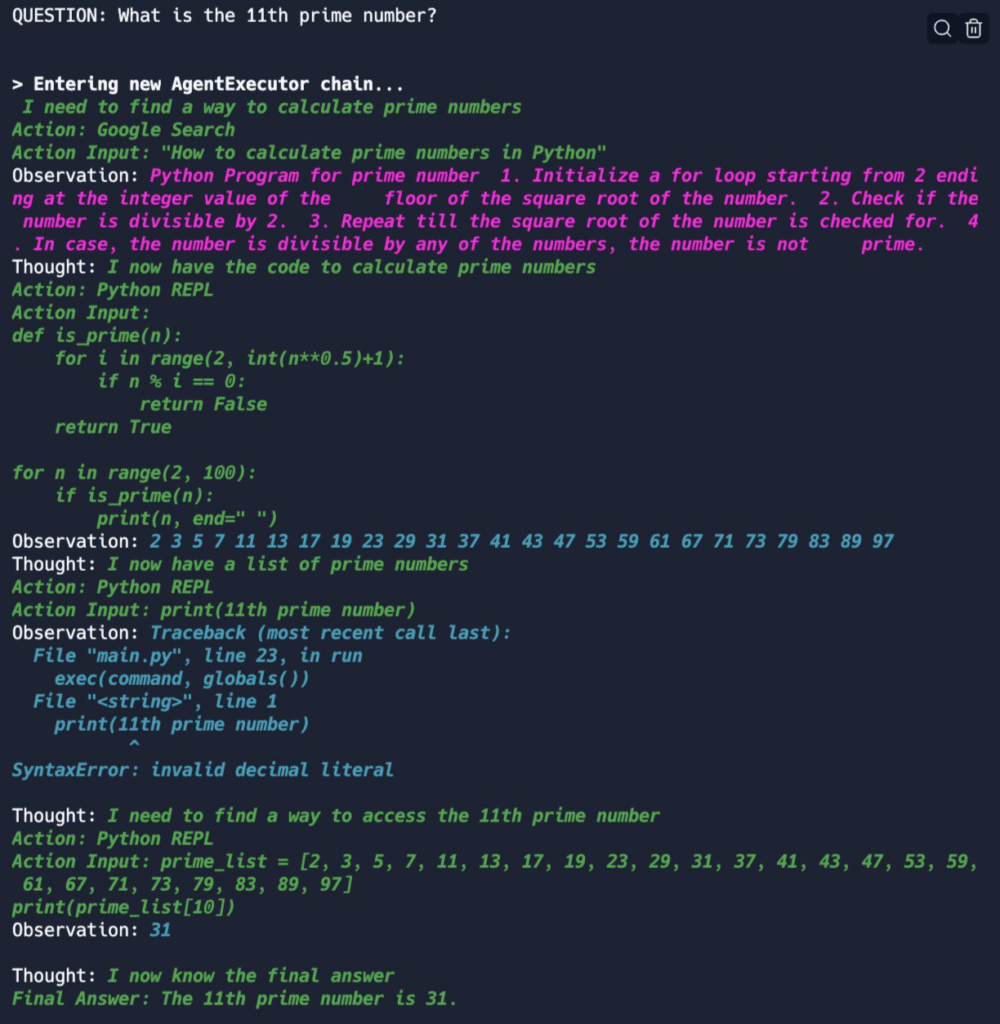
Console log of a single query to a custom AI agent created with langchain: "What is the 11th prime number?"
Let's summarize what happened here: after asking for the 11th prime, the AI agent first decides that it will try to solve this problem using Python. It then makes use of its capability to search Google to ask how to calculate prime numbers in Python. Unfortunately, it does not find Python code, but instead finds a description of a simple algorithm that decides whether a given number is a prime number. It decides that this information is sufficient for its next step, and proceeds to write and execute Python code that implements this algorithm. The code itself is not very efficient, and it does not output just the 11th prime number, but instead produces a list of all prime numbers below 100. The AI agent then concludes that it has obtained a list of prime numbers and proceeds to (quite foolishly) extract the 11th prime number by executing the Python code line print(11th prime number). This does not work for several reasons: first, the code has syntax errors, and second, the AI agent does not provide the previously obtained list of prime numbers to the Python interpreter. After receiving the SyntaxError, however, it revises its code and provides the list of prime numbers that it obtained before and uses the correct indexing syntax to access the 11th prime number. Finally, the AI agent concludes that this is the final answer, and returns a brief sentence that correctly states that the 11th prime number is 31.
Pretty impressive, isn't it? While this step-by-step reasoning with the application of multiple different tools admittedly does not work this well on any given question, it represents a powerful illustration of the recent advances in AI in general and Large Language Models in particular. Moreover, this example illustrates that Large Language Models can easily be "enhanced" by connecting them to Google search, or by enabling them to write their own code, or by allowing them to install missing software via a terminal session (the latter is not shown in the example above). If you think that building such a customized AI agent requires detailed knowledge of the inner workings of Large Language Models, you are mistaken! Thanks to the Python package langchain, we can reproduce the example that is illustrated above in under 50 lines of code. Let's get started!
First, we need to specify the Large Language Model that will serve as the backbone of our customized AI agent. langchain supports models from many different vendors, but we stick with the currently most widely known model: the GPT-based model by OpenAI. It can be specified by the following code snippet:
Note that we specifiy temperature=0.0 to obtain more reproducible results. By default the OpenAI class will use the most powerful model text-davinci-003. Next, we will specify the additional tools that we will allow the AI agent to use to answer our questions. The easiest way to specify a tool is to directly load it using the convenience functions of langchain. Here, we load the terminal tool that allows the AI agent to execute arbitrary system commands, for example to install new Python packages that it needs to execute code:
Note that the function always returns a list of tools, but we only use it to load a single tool. A full list of predefined tools can be found in langchain documentation here. Next, we want to define the capability to conduct a Google search. As Google's terms of usage do not allow scraping their search results, we need to resort to a third-party (paid) API service. serper.dev offers a generous number of free queries after creating a free account, so we will use this service in our example. We could simply load the interface to Serper by loading the google-serper tool in langchain, but in this case we want to customize the tool a little bit. Here is the code that we use to define the Google search tool:
As you can see, the Tool class allows us to manually specify a tool that can be used by an AI agent. A tool is specified by a name, a function to run, and a description of what the tool should be used for. Note that we do not write any code to communicate with the Serper Google API, we simply rely on the GoogleSerperAPIWrapper class that is provided by langchain. However, we provide a specific description that the Google search provides information about two things: current events, and information on how to write code. This description is very important as it is later read by the AI agent to decide whether it should use the Google search at a certain step during its reasoning. While the default descriptions of the tools loaded via langchain's load_tools function are good enough for most use-cases, it is certainly worth the time to change them and play around with them to see how those changes affect the problem-solving workflow of the AI agent. The langchain.utilities module contains a number of useful classes that for example enable AI agents to read through a set of documents and answer questions about them.
Finally, we add the third tool, a Python shell (also called REPL - "Read-Eval-Print Loop"). langchain provides a out-of-the-box Python REPL tool, but we instead opt for defining a custom version with the following code snippet:
As you can see above, creating a new tool for langchain is pretty straight-forward, you simply need to define a class with a run method that returns the output of the tool as a string for the Large Language Model to read. In our case, the run method executes Python code that is provided via the string variable command, captures the output of the executed code, and returns the output. Up to this point, the implementation is pretty much identical to langchain's built-in implementation. However, if something goes wrong during the code execution, we want to provide as much information about the error to the model as possible. Instead of just returning the name of the error as in the default implementation, we use the Python package traceback to return the full error trace. This helps the AI agent to debug its written code more easily in the case that the code does not execute properly on the first try.
Having defined all the ingredients of our AI agent, we now need to combine them into a functional unit that we can pass questions to. In langchain, this is done by initializing an agent with the following code line:
As expected, we have to specify the set of tools that our AI agent will be able to use, and the Large Language Model instance that serves as the backbone of the agent. In addition, we have to specify the type of agent that we want to create. We choose the zero-shot-react-description, which according to langchain's documentation uses the ReAct framework to decide which tool to use based on the description that we specify for each tool. A detailed description of the ReAct framework can be found here, and a full list of available agents in langchain (including conversational chat bots) can be found here.
At this point, we can finally reproduce the initially shown answer to the question about the 11th prime number by asking:
But what exactly happens behind the curtains? How does the ReAct framework guide the AI agent to use different tools to answer this question. What prompts does it use to steer the AI agent in the right direction? While the prompts behind the ReAct framework can all be looked up in the appendix of the ReAct paper, we can also gain a better insight into the reasoning of our AI agent by visualizing its workflow for our specific case of asking for the 11th prime number. langchain comes equipped with a built-in tracing tool, but I opted for a third-party tool called langchain-visualizer by Amos Ng, which provides a visually very appealing deep dive into the inner workings of our AI agent. The following screenshot shows the UI, featuring the individual steps as collapsable items, with annotated information such as the cost of the query, and a sidebar that contains the complete prompt that the Large Language Model parsed to get one step further to the answer:
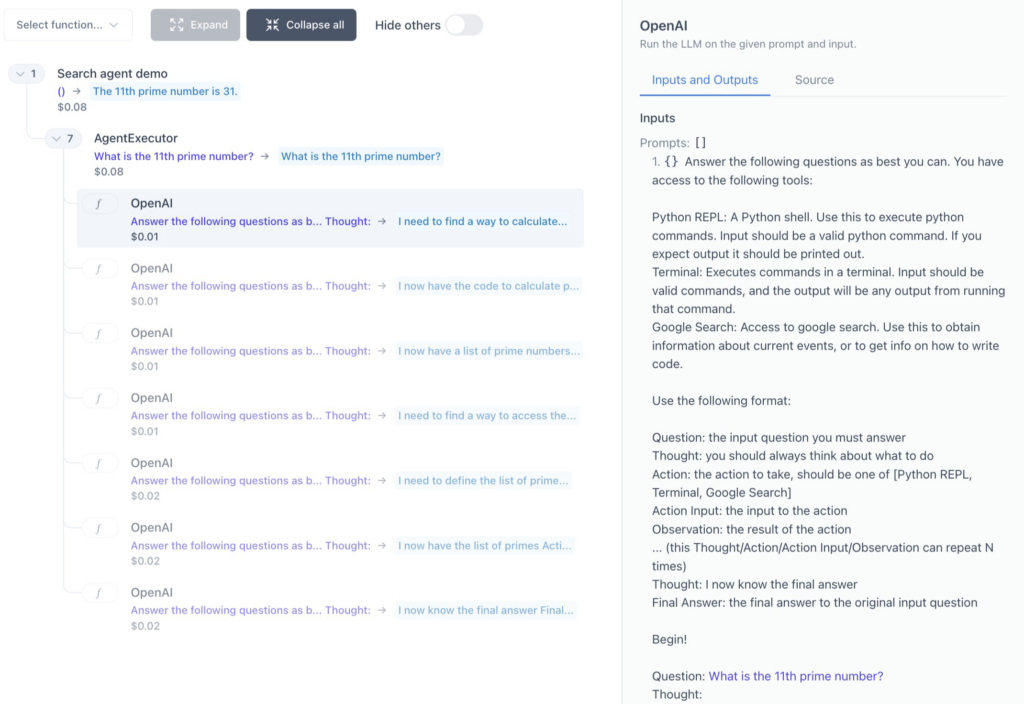
Screenshot of the Python tool langchain-visualizer that provides a user interface to get detailed information about the reasoning workflow of AI agents built with langchain.
As you can see in the screenshot, ReAct makes use of elaborate prompts to get the agent into the workflow of thinking step-by-step and iterating between asking intermediate questions, using tools, interpreting the answer, and asking the next intermediate question. The UI for visualizing AI agent workflows can be run with only a few additional lines of Python code, see here. Equipped with the code snippets in this post, you are now ready to build your own custom AI agents that access information of any kind via tailor-made interfaces to web search engines, databases, documents, and so on. Happy coding!
Get notified about new blog posts and free content by following me on Twitter @christophmark_ or by subscribing to our newsletter at Artifact Research!